Cuando el negocio se mira al espejo
Cualquier producto que ofrezca un catálogo a sus usuarios —ya sea contenido, música, comida o ropa— necesita en algún momento segmentar. Necesita agrupar productos en categorías que tengan sentido y, sobre todo, necesita entender a sus usuarios para poder recomendarles cosas que les gusten. Y aquí es donde suele aparecer el primer pecado original: las categorías se definen desde dentro, desde la visión que el equipo de producto y negocio tiene de su propio catálogo. En una plataforma de streaming, por ejemplo, alguien decide que el catálogo se organiza por género: acción, comedia, drama, terror, documental… Categorías limpias, ordenadas y, sobre todo, fáciles de defender en una reunión. El problema es que esas categorías no describen al usuario, describen al negocio. Y son cosas muy distintas.
La realidad del usuario suele ser bastante más transversal de lo que nuestro organigrama está dispuesto a admitir. Alguien que adora las historias con giros imposibles puede disfrutar por igual de un thriller, de una comedia negra y de un documental de true crime, contenidos que viven en tres categorías completamente distintas. Si nuestro modelo mental sólo entiende de géneros, nunca seremos capaces de detectar a ese tipo de usuario, ni mucho menos de recomendarle el siguiente título que le va a gustar. Estamos viendo al usuario a través de la lente que hemos construido nosotros, y esa lente tiene un campo de visión muy limitado.
A esto me gusta llamarlo segmentar desde el ego: asumir que las categorías que tienen sentido para nosotros son las mismas que tienen sentido para el usuario. Es un sesgo silencioso y muy cómodo, porque encaja con cómo está estructurada la empresa, con cómo se organiza el catálogo en la base de datos y con cómo razonan los equipos. Pero es un sesgo igualmente. La única forma de salir de él es invertir la dirección de la pregunta: en lugar de preguntarnos ¿en qué categorías encajan mis productos?, preguntarnos ¿qué patrones aparecen cuando observamos lo que realmente eligen mis usuarios?.
Y aquí es donde entra la herramienta que protagoniza este artículo. ¿Te has preguntado alguna vez cómo es posible que Netflix te recomiende una serie con un "porque viste X" y acierte de pleno, aunque las dos series no tengan apenas nada en común a primera vista? Detrás de ese tipo de recomendaciones, salvando las distancias, hay sistemas que comparten una misma idea con las Restricted Boltzmann Machines: son especialmente buenas descubriendo factores latentes que explican el comportamiento observado, aunque nadie se los haya enseñado de forma explícita. No les decimos qué buscar, simplemente les damos los datos de consumo de nuestros usuarios y dejamos que sean ellas las que destilen las categorías reales que se esconden detrás. Veremos en seguida cómo funciona esto, pero antes conviene entender, aunque sea superficialmente, qué es exactamente una RBM.
Qué es una Restricted Boltzmann Machine
Una Restricted Boltzmann Machine, o RBM, es un tipo concreto de red neuronal estocástica compuesta por sólo dos capas: una capa visible y una capa oculta. La capa visible es donde introducimos los datos que observamos del mundo real —por ejemplo, qué películas ha visto un usuario en una plataforma de streaming—, mientras que la capa oculta es donde la red intenta representar los factores latentes que explican esos datos, es decir, las razones que están por debajo de lo que el usuario consume.
Ambas capas están conectadas entre sí mediante pesos, pero con una restricción importante, y de ahí su nombre: las neuronas dentro de una misma capa no están conectadas entre sí. Las unidades visibles sólo se conectan con las ocultas, y viceversa. Esta restricción puede parecer un detalle menor, pero es precisamente lo que hace que la red sea computacionalmente tratable y lo que diferencia a una RBM de una Boltzmann Machine clásica, donde todo está conectado con todo y entrenarla se convierte en una pesadilla.
Lo de estocástica tampoco es un adorno. A diferencia de una red neuronal tradicional, donde una neurona se activa con un valor determinista (por ejemplo, el resultado de una función de activación aplicada sobre la suma ponderada de sus entradas), en una RBM cada neurona se activa o no se activa con una determinada probabilidad. Si introducimos los mismos datos dos veces, podemos obtener activaciones ligeramente distintas. Es una red que abraza la incertidumbre como parte de su naturaleza, y eso resulta ser una ventaja a la hora de descubrir patrones, porque le permite explorar configuraciones que una red determinista descartaría de entrada.
¿Y qué representan exactamente los pesos? Cada peso conecta una unidad visible con una unidad oculta, y nos indica lo fuertemente que esa unidad oculta se asocia con esa unidad visible. Un peso muy positivo significa que cuando esa unidad visible está activa, la unidad oculta tiende a activarse también. Un peso muy negativo significa lo contrario: su presencia suprime a la unidad oculta. Y un peso cercano a cero significa que apenas tienen relación. Si nos quedamos con una sola idea de esta sección, que sea esta: los pesos son lo que el modelo ha aprendido sobre la relación entre lo que vemos y lo que se esconde detrás.
No vamos a entrar aquí en cómo se entrena la red ni en los detalles matemáticos que hay detrás —cosas como la función de energía, el muestreo de Gibbs o el algoritmo Contrastive Divergence merecen un artículo aparte por sí mismas, y prometo escribirlo más adelante—. Lo importante para lo que vamos a ver a continuación es tener claro el esqueleto: dos capas, conexiones bidireccionales con pesos, activaciones probabilísticas, y un objetivo claro de aprender los factores latentes que explican los datos. Con eso nos basta.
El experimento: somos una empresa de comida a domicilio
Para ver todo esto en acción, vamos a ponernos en la piel de una empresa ficticia de comida a domicilio, al estilo de Wetaca o Knoweats. Tenemos un catálogo de doce platos: tacos al pastor, quesadillas, totopos con jalapeños, rigatoni carbonara, lasaña, risotto, fabada asturiana, lentejas con chorizo picante, sopas de ajo, kimchi chigae, sushi y pad thai. Si os fijáis, el catálogo está organizado en torno a cuatro categorías de negocio bien claras: mexicano, italiano, cuchara y asiático. Tres platos por categoría. Limpio, ordenado, y muy reconocible desde el lado del producto.
Por otro lado, tenemos un histórico de pedidos de 240 usuarios actuales, donde sabemos qué platos ha pedido cada uno. Ese va a ser el alimento de nuestra red: cada usuario es un vector de doce posiciones, una por plato, con un 1 si lo ha pedido y un 0 si no. Nada de etiquetas, nada de categorías, nada de metadatos. Sólo el comportamiento puro.
Con ese histórico entrenamos una Restricted Boltzmann Machine con doce unidades visibles (una por plato) y seis unidades ocultas. ¿Por qué seis y no cuatro? Precisamente para darle margen a la red. Si le hubiéramos puesto cuatro unidades ocultas, le estaríamos sugiriendo de forma implícita que reconstruya nuestras cuatro categorías de negocio. Al darle seis, le estamos diciendo: "oye, si crees que aquí hay más factores de los que nosotros vemos, tienes sitio para descubrirlos". Spoiler: los hay.
El código completo del experimento, junto con el dataset de entrenamiento y los scripts para reproducirlo, está disponible en este repositorio de GitHub. En este artículo no nos vamos a centrar en el código, sino en interpretar lo que la red ha aprendido. Y para eso, lo que viene a continuación es donde empieza la diversión.
Lo que aprendió la red: el hallazgo del picante
Una vez entrenada la red, llega el momento más interesante de todo el experimento: abrir el capó y mirar qué ha aprendido. Y lo que ha aprendido vive, fundamentalmente, en la matriz de pesos: una tabla con tantas filas como platos (doce) y tantas columnas como unidades ocultas (seis). Cada celda nos dice cómo de fuerte es la asociación entre ese plato y ese factor latente. Así es como queda nuestra matriz tras el entrenamiento:
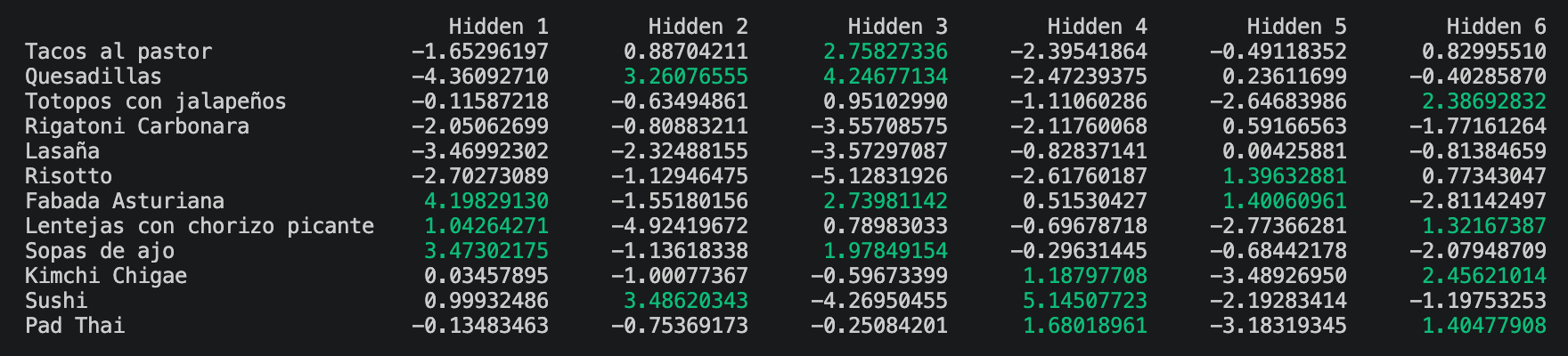
Pequeña guía de lectura: los valores en verde son pesos positivos, es decir, platos que activan esa unidad oculta. Los valores en blanco son pesos negativos o cercanos a cero, platos que esa unidad oculta no asocia o incluso suprime.
Si recorremos las columnas una a una vemos que la red ha redescubierto, en buena medida, las categorías que nosotros teníamos en mente. La unidad 1 se activa con fabada asturiana, lentejas con chorizo picante y sopas de ajo: tenemos el factor cuchara. La unidad 3, donde la suma de pesos positivos es mayor, agrupa tacos al pastor, quesadillas y totopos con jalapeños: factor mexicano. La unidad 4 se activa con sushi, pad thai y kimchi chigae: factor asiático. Y la unidad 5 se asocia con rigatoni carbonara, lasaña y risotto: factor italiano. Hasta aquí, ningún sobresalto: la red, sin que nadie le pase ni una etiqueta, ha reconstruido por su cuenta el mapa que el negocio ya tenía dibujado en la pizarra. Esto, por sí solo, ya es un buen indicador de que el entrenamiento ha funcionado.
Y entonces llegamos a la unidad 6. Atentos a qué platos se activan con ella: totopos con jalapeños, lentejas con chorizo picante, kimchi chigae y pad thai. Cuatro platos que, sobre el papel, viven en cuatro categorías de negocio distintas: mexicano, cuchara, asiático y asiático otra vez. Cuatro platos que, si te fijas, comparten una única cosa en común: todos pican. La red ha descubierto, sin tener ni una sola etiqueta de picante en sus datos de entrenamiento, que existe un factor latente que atraviesa todo el catálogo y que se llama tolerancia al picante.
Y aquí está el momento eureka del experimento. La empresa había definido cuatro categorías —mexicano, italiano, cuchara, asiático— y estaba convencida de que ese era el mapa correcto para entender a sus usuarios. La RBM, simplemente observando lo que la gente pedía, ha descubierto una quinta dimensión que la empresa no había contemplado, y que probablemente sea más predictiva del comportamiento futuro de un usuario que cualquiera de las cuatro originales. Porque alguien que ama el picante seguirá amando el picante, esté pidiendo mexicano, asiático o cuchara. Es un factor más estable y más profundo que la cocina regional. Si nos hubiéramos quedado en las cuatro categorías originales, jamás habríamos detectado a este tipo de usuario: la red no ha hecho magia, simplemente ha mirado los datos sin los filtros mentales con los que los miramos nosotros.
Hay una última observación que merece la pena hacer antes de pasar adelante. Si has estado atento, te habrás dado cuenta de que nos hemos saltado la unidad 2 en el recorrido. No es un olvido: si miramos sus pesos, no encontramos ningún patrón coherente, sólo activaciones dispersas que no apuntan a ninguna categoría reconocible ni a ningún factor latente claro. Es, simplemente, una unidad redundante: la red no ha sabido qué hacer con ella y podríamos descartarla sin perder capacidad explicativa. Esto enlaza con uno de los mayores trucos a la hora de trabajar con una RBM: elegir correctamente cuántas unidades ocultas se ponen. Demasiado pocas y la red se ve forzada a comprimir factores distintos en una misma unidad, perdiendo información. Demasiadas y nos pasa lo que aquí: aparecen unidades que no aportan nada y sólo añaden ruido al modelo. En este experimento hemos puesto seis a propósito, sabiendo que probablemente sobrara alguna, justo para mostrar este efecto. En un escenario de producción, lo habitual es entrenar con distintos tamaños de capa oculta y quedarse con el que mejor equilibrio ofrece entre capacidad y simplicidad.
Recomendando a usuarios nuevos: el sistema en acción
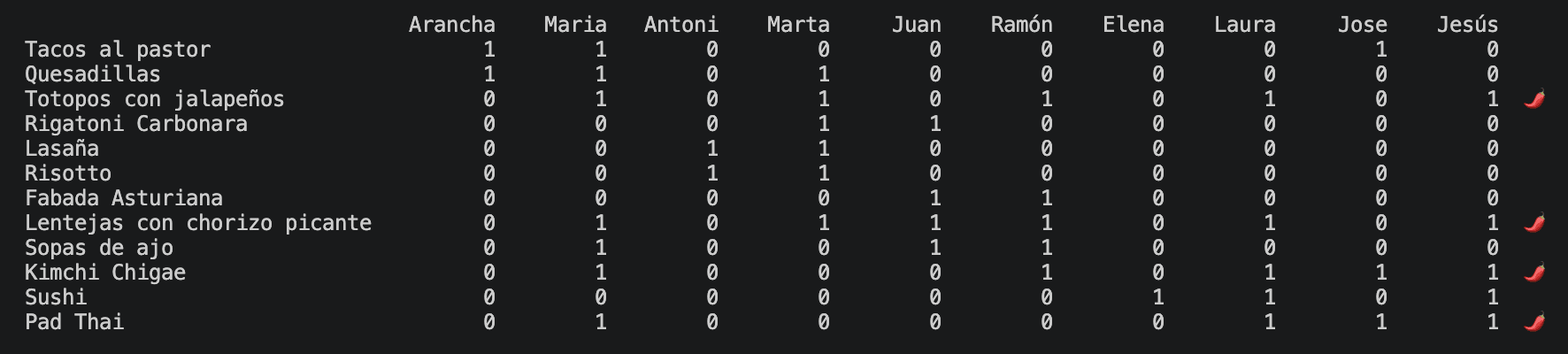
Ya tenemos una red entrenada que conoce el catálogo y los factores latentes que lo atraviesan. La siguiente pregunta es la que de verdad interesa al negocio: ¿cómo usamos esto con un usuario que acaba de aterrizar en la plataforma? Imaginemos que llegan diez usuarios nuevos y que, en su onboarding, les pedimos que marquen los platos que han probado o les apetecería probar. Estas son sus preferencias:
Hasta aquí, lo único que tenemos sobre estos usuarios es un puñado de 1 y 0. Ninguna etiqueta, ninguna categoría asignada, ningún historial. Lo interesante es lo que ocurre cuando pasamos cada uno de esos vectores por la red: en lugar de ver platos, la red empieza a ver factores. Concretamente, calcula la probabilidad de que cada unidad oculta se active para ese usuario, dándonos su perfil en el espacio de factores latentes:

Y aquí es donde el sistema deja de ser una curiosidad académica y empieza a ser útil. Fijémonos en María, que ha marcado tacos al pastor, quesadillas, totopos con jalapeños, lentejas con chorizo picante y pad thai: la red identifica que sus unidades dominantes son la 3 (mexicano) y la 6 (picante), con activaciones cercanas a 1. Es una usuaria que ama el picante en clave mexicana. Antoni, que ha marcado lasaña y risotto, activa fuertemente la unidad 5 (italiano) y nada más: amante del italiano sin complicaciones. Marta es el caso más interesante: ha marcado quesadillas, rigatoni carbonara, lasaña, risotto y lentejas con chorizo picante. Aunque la mayoría son platos italianos, su unidad dominante no es la 5 sino la 6. La red la ha identificado como una usuaria a la que el italiano le gusta, sí, pero a la que lo que de verdad la define es la tolerancia al picante. Laura y Jesús, por su parte, comparten un perfil casi idéntico construido sobre totopos con jalapeños, lentejas con chorizo picante, kimchi chigae, sushi y pad thai: asiático y picante con activaciones casi máximas.
Y aquí es donde se abren las posibilidades de recomendación cruzada. A Marta, italianófila y picantófila, le podríamos recomendar perfectamente un pad thai o unos totopos con jalapeños, platos que viven en categorías de negocio que ella ni siquiera ha tocado pero que comparten su factor latente más fuerte. A Arancha, en cambio, que ha marcado tacos al pastor y quesadillas, no le ofreceríamos unos totopos con jalapeños por mucho que sean mexicanos: su unidad 6 está prácticamente apagada, indicándonos que el picante no es para ella. Lo mismo ocurre con Elena, que ha marcado totopos con jalapeños, sushi y kimchi chigae pero cuya unidad 6 sigue siendo baja: la red detecta que su interés por esos platos no viene del picante sino de la cocina asiática y de cierta curiosidad transversal. Estamos pasando de recomendar por categoría a recomendar por afinidad latente, que es un salto cualitativo importante. Y, como nota al margen, también nos sirve para validar lo que sospechábamos en la sección anterior: si miramos la columna de la unidad 2, sus activaciones son erráticas y no aportan información útil sobre ningún usuario en particular. La redundancia se confirma también en el comportamiento.
Implicaciones para producto y negocio
Lo que hemos visto con el catálogo de comida se puede trasladar prácticamente sin cambios a cualquier producto con catálogo y usuarios: una plataforma de streaming, una tienda online, un servicio de música, un agregador de noticias. En todos esos escenarios conviven dos mapas: el que dibuja el equipo de negocio sobre la pizarra y el que está realmente grabado en el comportamiento de los usuarios. Las RBM, y en general las técnicas de descubrimiento de factores latentes, nos permiten mirar el segundo mapa sin tener que abandonar el primero.
La clave está en entender que las categorías de negocio no son falsas, simplemente son incompletas. Mexicano, italiano, cuchara y asiático siguen siendo útiles para organizar un catálogo, para construir un menú o para hacer marketing. Pero como mapa para entender al usuario, son una capa más entre varias. El picante era una de esas capas ocultas en nuestro experimento; en otros productos serán cosas como la duración preferida del contenido, el tono emocional, la sensibilidad al precio o cualquier otro patrón que el equipo no haya pensado en formalizar. La pregunta interesante no es ¿cuáles son mis categorías?, sino ¿qué dimensiones está utilizando mi usuario para tomar decisiones que yo todavía no estoy midiendo?.
Y conviene cerrar esta sección con una advertencia honesta: nada de esto sustituye al criterio del equipo de producto. Una RBM no te dice qué hacer, te dice qué patrones existen. Interpretarlos, ponerles nombre y convertirlos en decisiones de catálogo, de UX o de marketing sigue siendo trabajo humano. Lo que cambia es la calidad de la información sobre la que tomamos esas decisiones: pasamos de discutir hipótesis a discutir evidencias.
Conclusiones
Hemos recorrido un experimento sencillo pero ilustrativo: una pequeña empresa ficticia de comida a domicilio, un catálogo de doce platos, cuatro categorías de negocio y una red neuronal estocástica con seis unidades ocultas. Con apenas eso, la RBM ha sido capaz de redescubrir por su cuenta las categorías que ya teníamos en mente y, lo más importante, de encontrar una dimensión adicional —el picante— que el negocio nunca había puesto sobre la mesa. A partir de ahí, hemos visto cómo esa misma red sirve para clasificar a nuevos usuarios en el espacio de factores latentes y abrir la puerta a recomendaciones que cruzan categorías de forma natural.
Lo que me gusta de este tipo de modelos es que nos obligan a cambiar la pregunta. En lugar de preguntarnos cómo organizar nuestro catálogo, nos invitan a preguntarnos cómo lo organiza el usuario en su cabeza. Y muchas veces, cuando dejamos que los datos respondan a esa pregunta, descubrimos que el mapa que teníamos dibujado en la pizarra era sólo una de las capas posibles. En próximos artículos profundizaremos en los detalles internos de una RBM —función de energía, muestreo de Gibbs y Contrastive Divergence— y en otras técnicas relacionadas que comparten esta misma filosofía de descubrir lo que está oculto a simple vista.
Enjoy!